
There are times when a Developer or DBA needs to determine the best performance options with transferring data through a linked server from point A to point B but may not know the best way to do it. In the following example, I am going to show you the differences between a PUSH and PULL process through linked server and how SQL Server processes the workload. This example uses the AdventureWorksDW2017 database and the FactInternetSales table.
To know the difference between the PUSH and or PULL method the main differences are where you are running your statement from and how you are using your syntax.
The PUSH method:
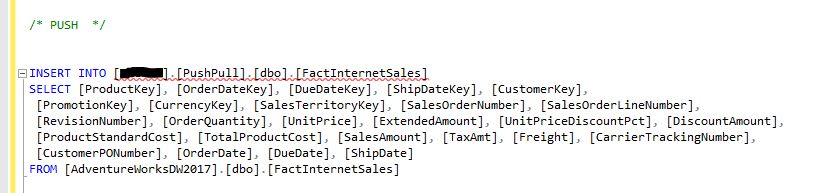
With this process, you going to INSERT the data into the Linked server. You can see an example of this below. Notice that it is doing the INSERT INTO through the linked server by placing the linked server string in the INSERT INTO portion. The statement is executed from where the base table is and selecting the data from.
The PULL Method:
With this method, you are inserting the data from a SELECT through the linked server. The linked server string information is placed in the FROM clause. The statement is being run from the server where you are inserting the data.

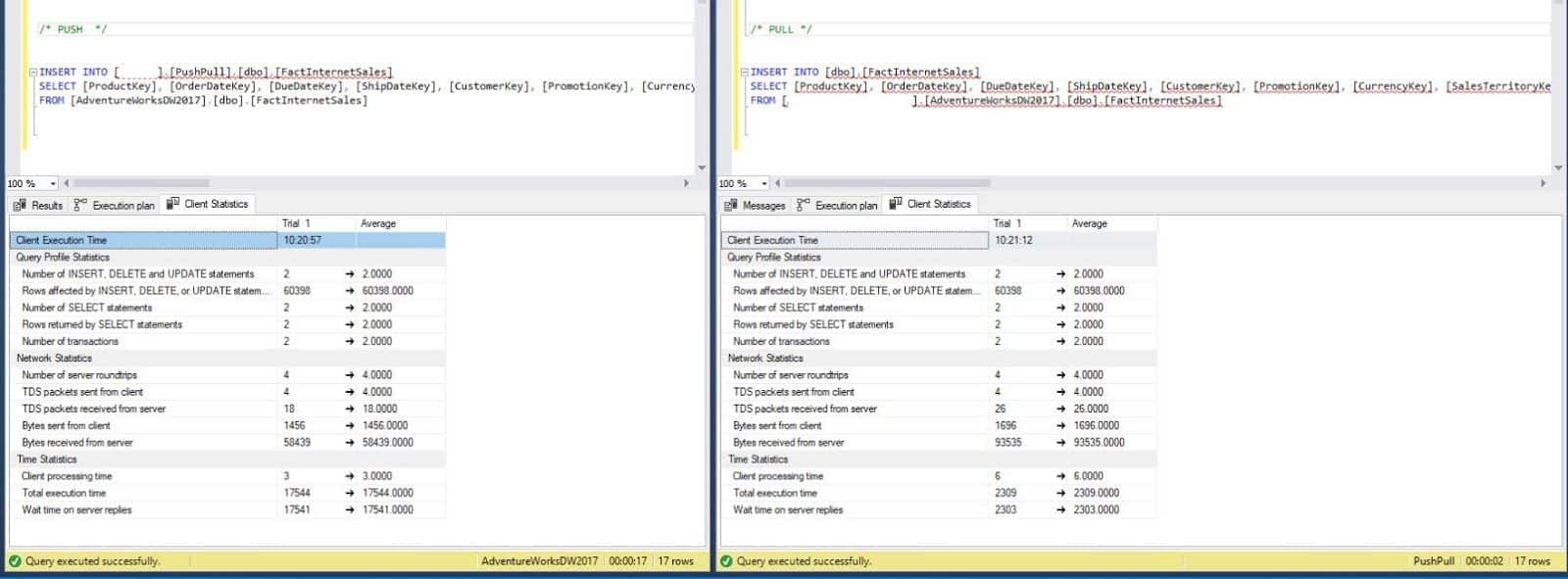
Looking at how this works below, you can see that the first query is using the PUSH method and the query to the right is using essentially the same INSERT query but using the PULL method instead of Pushing it as the first does. Digging into the details with Client Statistics, you can see that the Query Profile Statistics are basically doing the same thing between the two of them. They have the same amount of statements, rows affected, transactions, etc. Things change when we start looking at the Network Statistics, but I think that can be expected by the methods that we are doing. Depending on if we are pushing or pulling also depends on how the data moves through the connections, which put the majority of the work on one side or the other, so this can be expected. You can see this in more detail by looking at the execution plan below and the differences in the execution plan and how it is processing the “remote” portions of the execution plans. Here is where it starts getting good. For the ones who need this data, they don’t really care about the number of packets and round trips that it takes, even though that does have an effect on the overall process. They just care about the time that it takes and want it as soon as they can get it. Completely understandable. Looking at the Time Statistics, we can start seeing major differences between the two. Even though the Client Processing time is doubled for the PULL method, the Total Execution Plan is a 13% of what the PUSH method is doing.
What does it mean in terms of actual numbers?
Looking at Query Windows between the two, you can see that the PUSH is taking 17 seconds and the PULL is only taking 2 seconds. Yes, this is a very basic query, but just think what happens when you start adding complexity with JOINS and other CONDITIONS…
Now let’s look at the Execution Plans between the two and how the SQL Engine determines what it needs to do to make it all happen. The PUSH method is using a “Remote Insert” with the use of a Clustered Index Scan utilizing 91% of the load. Scans are not always good and they are not always bad. In this case, we are not using any conditions that reference the clustered index but you can see how it is putting most of the workload on the scan at 91%. With the PULL method, you can see that it is using a “Remote Query” which does not have the performance impact that the remote insert does. The cost for the Remote Query is at 65% and further balanced out with a Clustered Index Search at 35%. The workload in this execution plan is more balanced throughout the entire process.
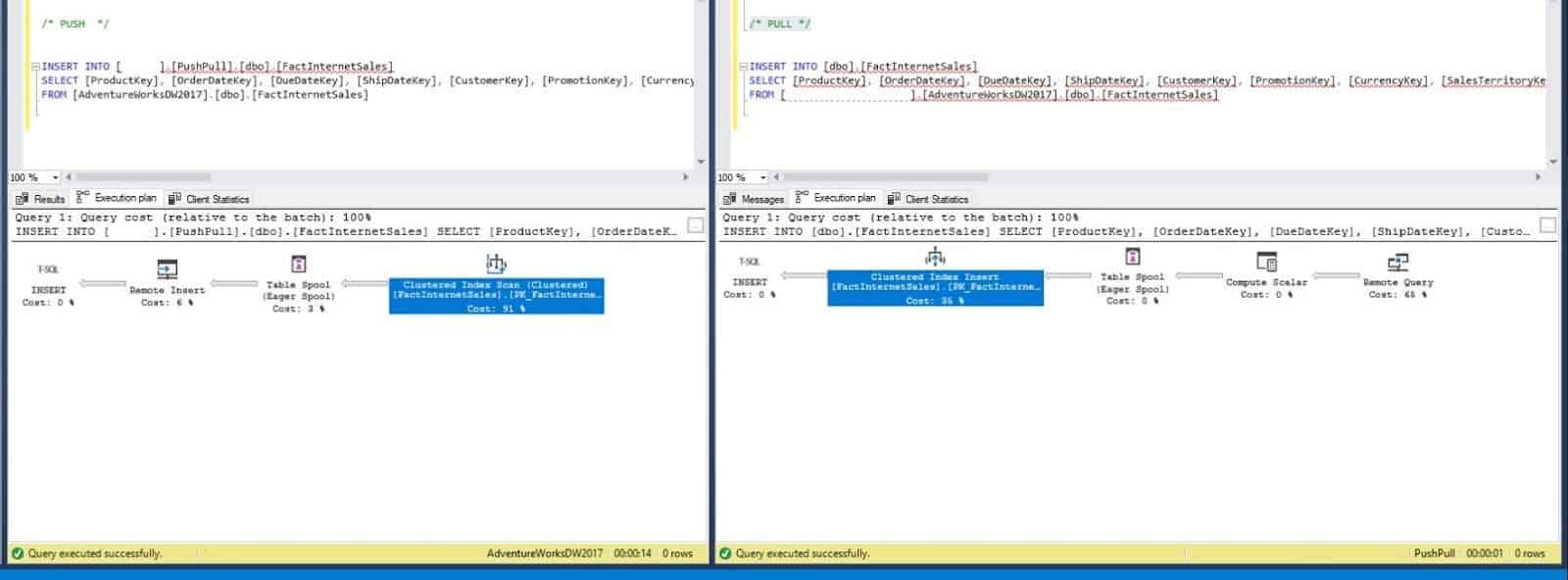
With this example, you can see the evidence in the Client Statistics of how different SQL Server handles PUSH vs PULL through linked servers. Your situations may vary but you should find in most situations that the PULL method is less resource intensive and you should get better performance because of it.